Sur cette page
Notre avis sur Artificial Analysis
Artificial Analysis est à ouvrir dès qu'un choix de modèle engage une API, un budget tokens ou une latence produit.
Il sert à sortir une shortlist de 3 à 5 modèles, puis à valider ces candidats sur vos propres exemples avant migration.
Les fonctionnalités principales de Artificial Analysis
Les fonctions principales de Artificial Analysis couvrent les usages qui comptent le plus au quotidien.
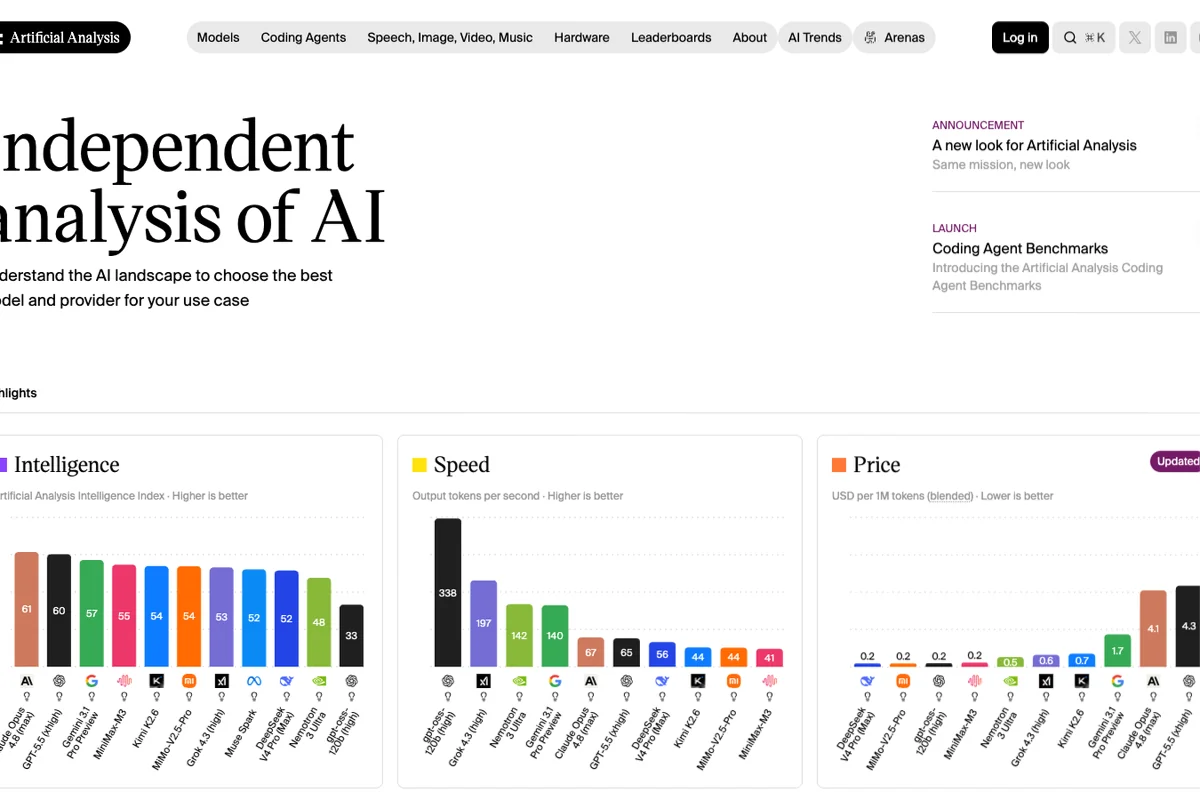
Compare intelligence, prix, vitesse, latence
Compare intelligence, prix, vitesse, latence, fenêtre de contexte et fournisseurs API dans une même lecture.
Méthodologie publique avec un Artificial
Méthodologie publique avec un Artificial Analysis Intelligence Index v4.0 fondé sur 10 évaluations, dont GDPval-AA, Terminal-Bench Hard, SciCode et GPQA Diamond.
Affiche des métriques concrètes pour un produit IA
prix par million de tokens, tokens par seconde, latence au premier token et taille de contexte.
API documentée pour récupérer les
API documentée pour récupérer les métriques principales des benchmarks, avec compte, clé API et attribution obligatoire.
Benchmarks séparés pour LLM, agents
Benchmarks séparés pour LLM, agents de code, image, vidéo et voix, ce qui évite de juger tous les modèles avec un score unique.
Très utile pour arbitrer entre
Très utile pour arbitrer entre GPT, Claude, Gemini, DeepSeek, Kimi, Mistral, Llama ou des fournisseurs API plus rapides avant de payer des tokens.
À qui s’adresse Artificial Analysis ?
Le bon profil dépend surtout du résultat à produire et de la fréquence d’utilisation.
Particulièrement adapté
- Développeur SaaS
- CTO ou lead IA
- Consultant IA
Moins adapté
- Utilisateur qui cherche seulement un chatbot personnel
- Équipe qui veut choisir un modèle sans benchmark interne
- Projet conformité ou sécurité qui exige un audit contractuel complet
En bref
Avantages et limites de Artificial Analysis
Ce qu’on aime
- Compare intelligence, prix, vitesse, latence, fenêtre de contexte et fournisseurs API dans une même…
- Méthodologie publique avec un Artificial Analysis Intelligence Index v4.0 fondé sur 10 évaluations, dont…
- Affiche des métriques concrètes pour un produit IA : prix par million de tokens, tokens par seconde,…
Ce qui peut frustrer
- Un score de benchmark ne remplace pas un test sur vos cas internes, surtout en français, avec PDF,…
- L'Intelligence Index principal est text-only et en anglais ; il faut croiser les évaluations multilingues…
- Les limites API diffèrent entre la documentation stable et la référence beta ; vérifiez le quota actif…
Prix Artificial Analysis : web gratuit, API et services
Comparez l’usage réel, le prix et la capacité incluse avant de choisir.
Plateforme webNotre choix$0+
Leaderboards publics pour modèles LLM, agents, image, vidéo, voix et…
Capacité :Selon usage
Free Data API$0+
API centrée sur les métriques principales des benchmarks
Capacité :Selon usage
Commercial API et servicesSur devis+
Données plus complètes pour partenaires
Capacité :Selon usage
Les offres supérieures couvrent les volumes et besoins d’équipe. Vérifiez toujours la source avant achat.
Analyse complète
Artificial Analysis passé au crible
Choisir un modèle IA pour une API, un agent ou une fonctionnalité SaaS n’a rien à voir avec choisir le chatbot le plus populaire du moment. Le mauvais modèle peut répondre trop lentement, coûter trop cher à gros volume, rater vos documents français ou imposer une fenêtre de contexte trop courte. Artificial Analysis sert justement à éviter ce premier mauvais tri.
La bonne manière de l’utiliser est simple : ouvrir le leaderboard, regarder ensemble intelligence, prix, vitesse, latence et contexte, puis sortir une shortlist de trois à cinq modèles. Après seulement, vous testez ces candidats sur vos requêtes, vos PDF, vos appels outils et vos contraintes de budget. Artificial Analysis ne décide pas à votre place. Il évite de tester quinze modèles au hasard.
Pourquoi consulter les benchmarks d’Artificial Analysis ?
Artificial Analysis est l’un des meilleurs points de départ quand le choix d’un modèle IA a une conséquence produit : coût d’inférence, temps de réponse, qualité de raisonnement ou stabilité d’une API. Le site ne se limite pas à un podium. Il montre l’Artificial Analysis Intelligence Index, le prix par million de tokens, les tokens générés par seconde, la latence au premier token, le temps de réponse total, la fenêtre de contexte et le type de modèle.
C’est précisément ce mélange qui rend l’outil utile. Si votre assistant support doit commencer à répondre vite, une latence faible peut compter davantage qu’un point gagné sur un score global. Si votre app résume des contrats longs, le contexte et le coût par million de tokens deviennent plus importants que la réputation du fournisseur. Si vous construisez un agent de code, les benchmarks coding et agentiques pèsent plus que le classement général.
La note de 4,5/5 reflète cette force, avec une réserve claire : Artificial Analysis est un filtre de décision, pas un oracle. Un modèle peut être très haut dans l’Intelligence Index et décevoir sur vos emails français, vos consignes de ton, vos extractions PDF ou vos appels outils. Pour un produit en production, un test interne de 50 à 200 exemples vaut souvent plus qu’une place gagnée dans un leaderboard.
Ma décision est nette : ouvrez Artificial Analysis si vous devez brancher une API, défendre un choix devant une équipe ou réduire un coût tokens. Passez votre chemin si vous cherchez seulement un chatbot personnel pour écrire un email ou résumer une page. Dans ce cas, Claude, ChatGPT ou Google AI Studio seront plus directs.
Quelles données de performance IA sont analysées ?
Le coeur du site est l’Artificial Analysis Intelligence Index. D’après la méthodologie officielle, la version v4.0 regroupe 10 évaluations, dont GDPval-AA, Terminal-Bench Hard, SciCode, AA-LCR, AA-Omniscience, IFBench, Humanity’s Last Exam, GPQA Diamond et CritPt. L’intérêt n’est pas de mémoriser tous ces noms. L’intérêt est de comprendre que le score mélange plusieurs familles de tâches : agents, code, raisonnement général et raisonnement scientifique.
Pour un lecteur non technique, l’impact est très concret. GDPval-AA regarde des tâches proches du travail économique. Terminal-Bench Hard teste des agents dans un terminal. SciCode parle aux développeurs qui manipulent du code scientifique. AA-Omniscience mesure la connaissance et les hallucinations. GPQA Diamond et CritPt tirent vers le raisonnement scientifique. Vous ne choisirez donc pas la même colonne pour un chatbot support, un copilote de code, un moteur de veille ou un agent qui manipule des fichiers.
Artificial Analysis ajoute aussi les métriques qui transforment un benchmark en décision. Le prix est exprimé en dollars par million de tokens. La vitesse indique combien de tokens sortent par seconde. La latence au premier token dit combien de temps l’utilisateur attend avant de voir la réponse commencer. La fenêtre de contexte montre la quantité de texte qu’un modèle peut recevoir dans une requête. Ces chiffres ont une conséquence directe : budget mensuel, sensation de lenteur, capacité à traiter un dossier long, confort d’un agent en direct.
Le site sépare enfin plusieurs univers : LLM, agents de code, image, vidéo, voix et fournisseurs API. C’est un bon signal de sérieux. Comparer une IA vidéo, une voix synthétique et un LLM dans un seul score global serait spectaculaire, mais peu utile pour acheter ou intégrer quoi que ce soit.
La limite à garder en tête est officielle : l’Intelligence Index principal est une suite text-only en anglais. Artificial Analysis publie des évaluations multilingues séparées, mais un produit francophone doit toujours vérifier ses propres requêtes. La décision raisonnable consiste donc à utiliser le score global pour réduire le champ, puis à tester vos cas français avant migration.
Accès gratuit et API : Tarifs Artificial Analysis
Artificial Analysis n’est pas présenté comme un SaaS classique avec un plan Pro public à comparer dans une grille marketing. Les leaderboards web sont accessibles gratuitement, et c’est le meilleur point de départ pour la majorité des lecteurs. Si vous faites une veille mensuelle, une sélection de modèles pour un prototype ou un benchmark ponctuel, le web gratuit suffit.
L’API demande plus d’attention. La documentation stable présente une Free Artificial Analysis Data API centrée sur les métriques principales : benchmarks, pricing, vitesse et latence. Elle exige un compte, une clé API dans l’en-tête x-api-key, une attribution à artificialanalysis.ai et conseille de ne pas exposer la clé côté client. Cette même documentation indique une limite de 1 000 requêtes par jour.
La référence beta affiche une lecture différente : tiers Free, Pro et Enterprise, avec 25 requêtes par jour en Free, 100 en Pro et un volume Enterprise provisionné manuellement. La bonne correction éditoriale est donc de ne pas promettre un quota unique. Si vous automatisez une veille modèle dans un dashboard interne, vérifiez la documentation active au moment de l’intégration, mettez les réponses en cache serveur et prévoyez un fallback si le quota descend.
Le coût réel arrive surtout après Artificial Analysis : dans le modèle que vous choisirez. À 10 millions de tokens mensuels, passer d’un modèle à 10 $/1M tokens à un modèle à 2 $/1M tokens représente environ 80 $ par mois. À 100 millions de tokens, l’écart approche 800 $. Le site n’a pas besoin de vendre un abonnement pour créer de la valeur : il peut simplement vous empêcher de brancher trop tôt un modèle trop cher.
Les besoins avancés passent par les services commerciaux : API plus complète pour partenaires, conseil, recherche marché, sélection technologique, analyse de coûts, déploiements dédiés et custom benchmarking. Ce n’est pas nécessaire pour une veille simple. C’est pertinent si une décision engage une roadmap, un budget API important ou un déploiement client.
Comparer les modèles IA sur Artificial Analysis →
La décision est courte : web gratuit pour présélectionner, API si vous automatisez, services commerciaux si le choix engage beaucoup d’argent ou de risque.
À qui s’adresse le comparateur Artificial Analysis ?
Artificial Analysis devient rentable dès qu’un mauvais choix de modèle coûte plus cher que le temps passé à comparer. Le profil le plus évident est le développeur SaaS qui branche une API dans une fonctionnalité payante. Il doit arbitrer entre qualité, coût, latence et stabilité. Le piège serait de tout confier au modèle premium du moment. C’est confortable. Ce n’est pas toujours rentable.
Un SaaS peut par exemple garder un modèle rapide et économique pour l’autocomplétion, un modèle plus fort pour les analyses complexes et un modèle à long contexte pour les documents lourds. Artificial Analysis aide à construire cette séparation. Le résultat n’est pas “le meilleur modèle IA”, mais une architecture plus saine : chaque usage reçoit un modèle adapté.
Le deuxième profil est le CTO, le lead IA ou le consultant qui doit justifier une recommandation. Dire “je préfère Claude” ou “GPT est meilleur” ne suffit plus quand le client demande le coût, la vitesse ou la robustesse. Artificial Analysis donne un langage commun : score, prix, latence, contexte, benchmark spécialisé. La décision reste humaine, mais elle ne repose plus seulement sur une impression de chatbot.
Les équipes produit y gagnent aussi. Un PM peut comparer une option rapide pour un chatbot support, une option à long contexte pour lire des contrats et une option coding pour un agent interne. La conséquence pratique est forte : la stack IA cesse d’être un pari unique et devient un portefeuille de modèles.
Le site est moins adapté à trois profils. Le premier est l’utilisateur qui veut seulement discuter avec une IA. Le deuxième est l’équipe qui veut une réponse définitive sans benchmark interne. Le troisième est le projet conformité, sécurité ou données sensibles qui exige contrats, DPA, audit fournisseur et analyse juridique. Artificial Analysis peut éclairer le choix technique, mais il ne remplace pas cette diligence.
Alternatives : Artificial Analysis face à LMArena et BenchLM
Le concurrent le plus utile à ouvrir en parallèle est LMArena. Son angle est différent : préférences humaines dans des duels conversationnels. Pour un chatbot support, le bon chemin consiste à utiliser Artificial Analysis pour coût, vitesse et latence, puis LMArena pour vérifier si les réponses plaisent vraiment dans des conversations courantes. Les deux outils ne mesurent pas la même chose, et c’est justement leur intérêt.
BenchLM pousse une autre logique : très grande densité de benchmarks, scores, données de prix, vitesse, historiques et exports. C’est excellent pour un audit profond ou une comparaison de modèles sur plusieurs familles d’évaluations. Artificial Analysis reste plus lisible quand la décision doit être prise vite par une équipe produit : quel modèle tester, combien il coûte, à quelle vitesse il répond, et quelle limite surveiller.
Hugging Face Open LLM Leaderboard reste pertinent si votre priorité est l’écosystème open source. Vous y vérifiez les modèles ouverts, les cartes modèles, les licences, les téléchargements et les possibilités de déploiement. Artificial Analysis est plus fort pour comparer dans une même lecture modèles propriétaires, modèles open weights, fournisseurs API et coûts d’inférence.
HELM garde enfin une valeur académique. Il est plus naturel pour une recherche, un audit méthodologique ou une comparaison rigoureuse de benchmarks. Pour une roadmap produit ou une intégration API, Artificial Analysis est plus actionnable.
La comparaison que beaucoup de fiches annuaire ratent est celle-ci : le classement qui aide un chercheur n’est pas toujours celui qui aide un produit. Un modèle très fort sur raisonnement scientifique peut être trop lent pour une réponse client. Un modèle très rapide peut être insuffisant pour un agent complexe. Un modèle open weights peut réduire le coût d’inférence si votre infra suit, mais coûter plus cher en maintenance si personne ne sait l’opérer.
Ouvrir le leaderboard Artificial Analysis →
Verdict final : essayez Artificial Analysis si vous devez comparer des modèles pour une API, un SaaS, un agent ou une décision client. Croisez-le avec BenchLM si votre audit doit être très large. Évitez de l’utiliser seul si votre décision touche la conformité, les données sensibles ou une migration production sans test interne.
Alternatives à Artificial Analysis
Ces options répondent à des priorités différentes : comparez d’abord le résultat attendu, puis le prix.
LMArena
Préférences humaines et comparaisons de réponses
Gratuit Voir l’analyseBenchLM
Vue multi-benchmarks très large
Freemium Voir l’analyseHugging Face Open LLM Leaderboard
Modèles open source et écosystème Hugging Face
Gratuit Voir l’analyseAvant de brancher une API
Comparez coût, latence et qualité sur Artificial Analysis
Ouvrez le leaderboard avec votre contrainte principale en tête : qualité, budget, vitesse ou contexte long.
FAQ sur Artificial Analysis
Artificial Analysis est-il gratuit ?
Oui, les leaderboards publics sont accessibles gratuitement. L'API dispose aussi d'un accès gratuit avec clé, mais ses quotas doivent être vérifiés dans la documentation active avant une automatisation.
Artificial Analysis donne-t-il le meilleur modèle IA ?
Il donne un très bon point de départ, pas une vérité universelle. Le bon modèle dépend de votre usage : raisonnement, code, coût par million de tokens, latence, contexte, langue et tolérance aux erreurs.
Peut-on utiliser Artificial Analysis pour choisir une API LLM ?
Oui. C'est l'un de ses meilleurs usages, car le site croise prix, vitesse, latence, contexte et performance. Il faut ensuite tester les candidats sur vos propres exemples avant migration.
L'Intelligence Index est-il fiable pour un produit en français ?
L'index principal est text-only et en anglais. Pour un produit francophone, croisez-le avec les évaluations multilingues publiées séparément et avec un jeu de requêtes françaises interne.
Quelle limite API faut-il retenir ?
La documentation stable mentionne 1 000 requêtes par jour pour l'API gratuite, tandis que la référence beta liste des tiers Free, Pro et Enterprise avec des quotas différents. Pour un usage automatisé, vérifiez la page officielle au moment de l'intégration.
Quelle alternative à Artificial Analysis choisir ?
LMArena est utile pour les préférences humaines, BenchLM pour une vue multi-benchmarks très dense, Hugging Face pour les modèles ouverts et HELM pour une approche académique.